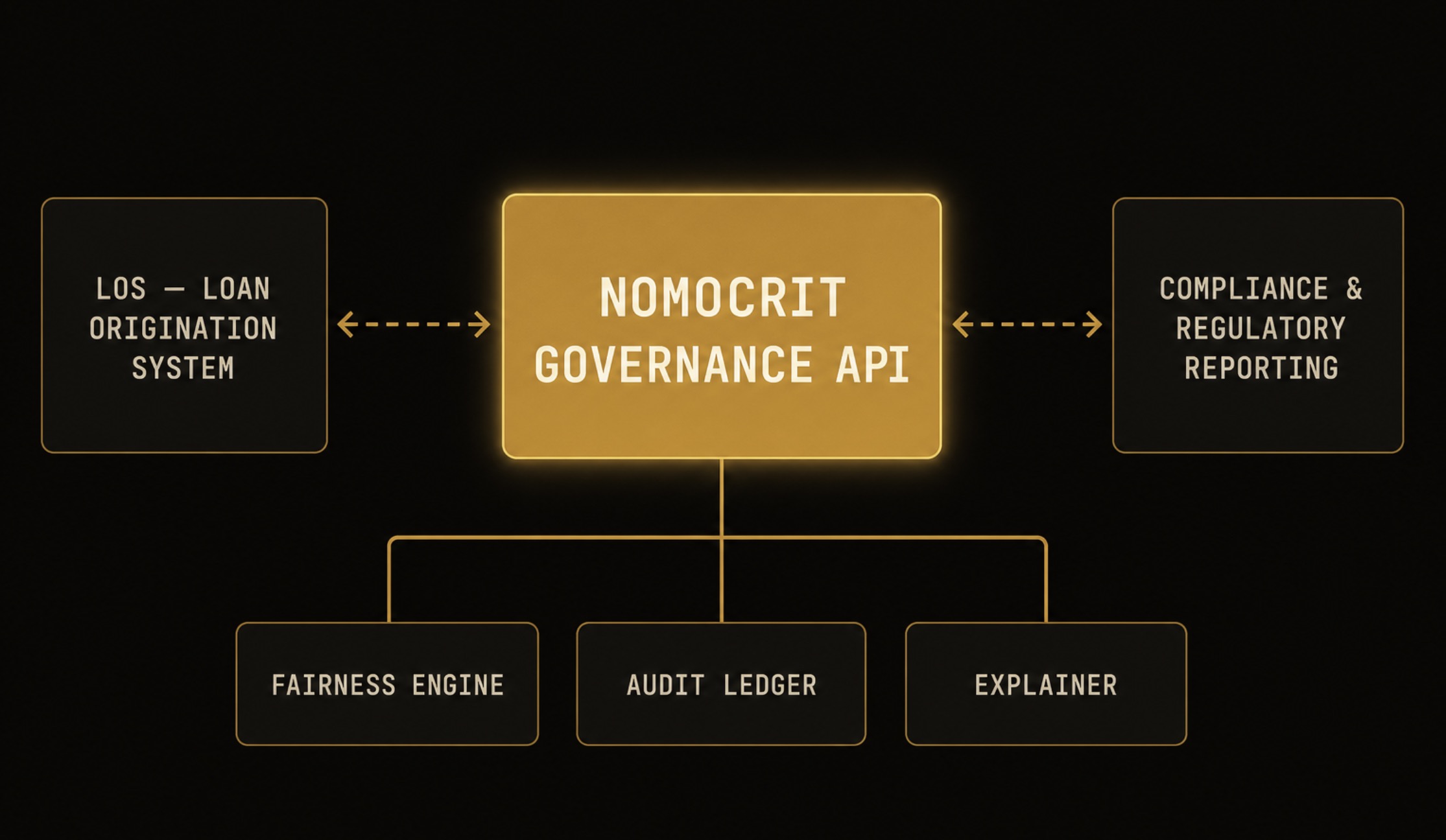
The Four-Layer Decision Governance Stack
A stateless, append-only architecture that makes every lending decision explainable, auditable, and fair — without touching your existing model infrastructure or scoring pipeline.

Raw Data Ingestion
NomoCrit accepts bureau data, lender proprietary features, and behavioural signals via a normalised JSON intake layer operating at decision latency. The input pipeline handles CIBIL, Experian, Equifax, and CRIF bureau response formats natively, with a configurable field-mapping layer for lender-specific proprietary data — no schema migration, no API replacement.
Raw features are normalised against a rolling population baseline computed over the preceding 90-day application window. This normalisation handles distribution shift between application cohorts without model retraining — the threshold engine adapts to the normalised distribution, not the raw feature distribution. Baseline updates are versioned and auditable.
Missing data is handled via deterministic imputation with a full audit trail. Every imputed value is recorded in the decision log with its imputation method and the population-level statistic used. This eliminates the class of silent feature substitution that creates unexplainable outcomes when a model encounters missing bureau fields in production.
Adaptive Threshold Engine
The core decision engine maintains per-segment approval thresholds calibrated against defined business acceptance criteria and fairness targets. Segments are defined by lender-configured population slices — bureau score band, loan type, geography, or application channel — allowing differential calibration without introducing disparate impact across protected characteristics.
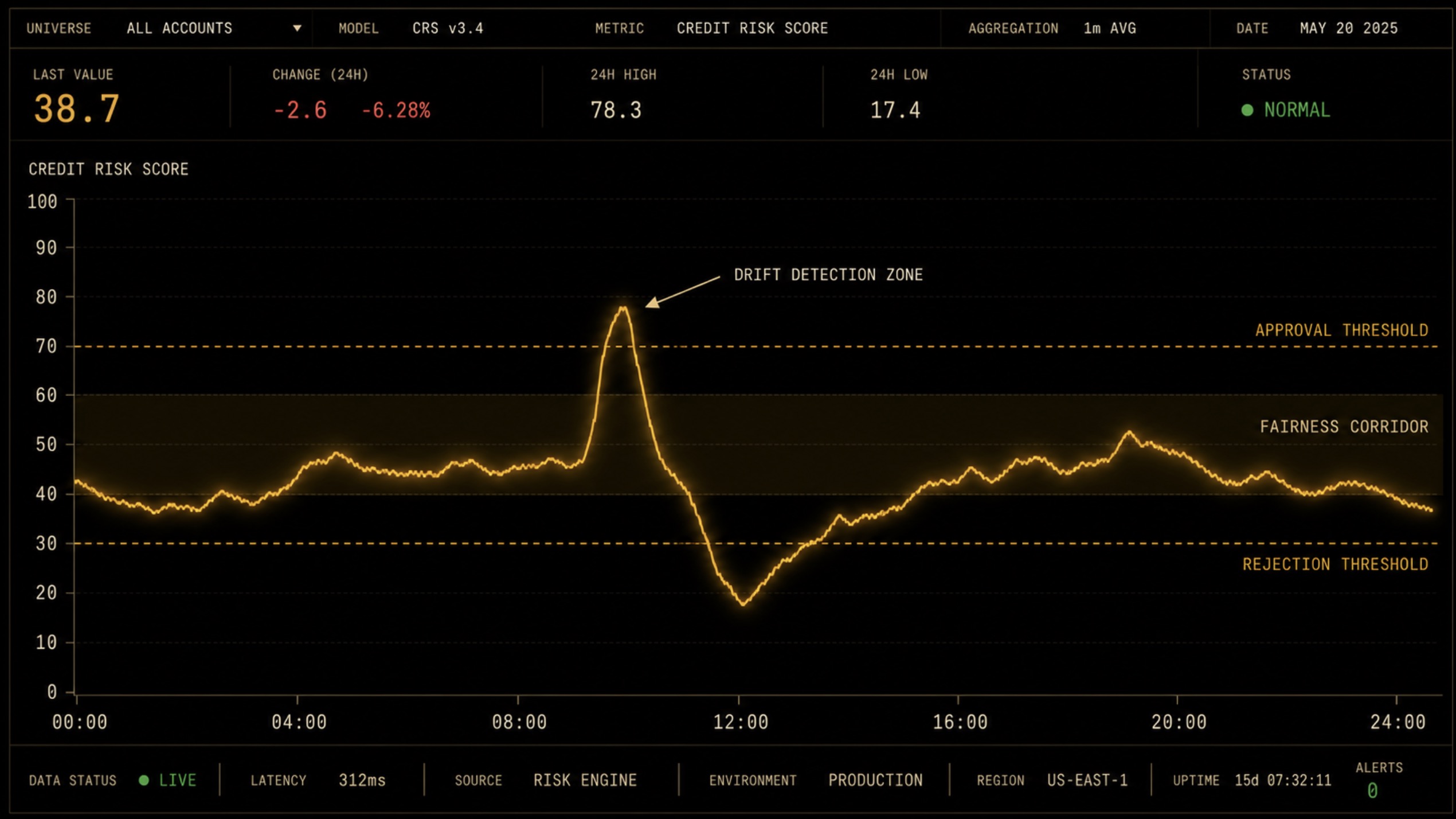
Threshold drift is monitored via KS statistic, Population Stability Index (PSI), and approval-rate disparity metrics, computed on a configurable cadence. When a monitored metric crosses a defined tolerance band, the recalibration pipeline activates automatically. Drift detection is independent of model performance — a model can be operationally stable while its operating population distribution shifts.
Recalibration produces a new threshold set against the current population distribution with a complete provenance record: the drift metric that triggered recalibration, the population window used, the recalibration algorithm version, and the resulting threshold values per segment. Human review is required before any threshold set is deployed to production. There is no silent threshold mutation.
Governance Layer
Every decision passes through a SHAP-based attribution engine that produces a ranked feature contribution vector. The vector is expressed in human-readable terms — feature names, contribution direction, and relative magnitude — rather than raw SHAP values. The explanation is generated at evaluation time: not reconstructed on demand, not approximated retrospectively.
The Grounds-of-Rejection (GoR) artifact is generated for every declined application at the moment of evaluation. It contains the primary rejection factors ranked by contribution, the contribution magnitude of each factor, the applicant's current distance from the approval threshold, and the available recourse pathways. The artifact satisfies the RBI Digital Lending Guidelines (RBI/2022-23/111) adverse-communication requirements and is generated in both machine-readable JSON and human-readable PDF.
Recourse pathways are generated deterministically from the feature contribution vector and a lender-configured recourse policy. Where a rejection factor is addressable — income documentation, bureau dispute, or existing credit utilisation — the pathway is explicit and time-bound. Where it is structural — credit history length, for instance — the pathway is stated as a conditional future-state. No recourse information is withheld.
Compliance Output
The audit log captures full evaluation context in an append-only schema at the moment of decision. Each log entry contains the complete post-normalisation input vector, model version identifier, active threshold set version, decision output, explanation vector, per-decision fairness metrics, and processing metadata including timestamps, data provenance markers, and the regulatory context.
Exports are formatted to the RBI Digital Lending Guidelines (RBI/2022-23/111) schema for adverse action communication and the DPDP Act purpose-limitation artifact format for data processing records. Export generation is automated — no manual annotation, no post-processing pipeline, no last-minute restructuring for an inspection. A 90-day audit export (target SLA for production deployments) can be produced in under four hours.
The DPDP artifact records the lawful basis for each data processing operation, the data categories processed, the retention period applied, and the status of data principal rights. It is generated as a by-product of the normal decision evaluation flow — not as a separate reporting step triggered by a compliance event.
| Input formats | JSON REST, Webhook, Batch CSV |
| Latency SLA | <150ms governance overhead per decision |
| Explainability | SHAP (TreeExplainer + KernelExplainer) + Rule extraction |
| Output artifact | JSON (structured) + PDF (human-readable) + Audit CSV |
| Integration | REST API, Python SDK (forthcoming), Webhook push |
| Data residency | India (Mumbai region, VPC-isolated) |
Enterprise deployment with Indian data residency.
VPC-Isolated Deployment
NomoCrit deploys within your cloud boundary. No decision data leaves your infrastructure perimeter.
Data Resident in India
All processing occurs within Mumbai region (ap-south-1). No cross-border data transfer.
Audit Trail Immutability
Decision ledger entries are append-only and cryptographically timestamped. No post-hoc modification is architecturally possible.
Real-time credit risk monitoring with drift detection.
Drops in between your LOS and compliance reporting.